日々の破片
| 著作一覧 |
2008-09-23
_ UTF-8のBOMについて
データファイルを読むのはアプリケーションなので、どうでも良いことのように思います。それをどうするかはアプリケーションが決めれば良い。
C:\Users\arton\tmp>type u8.rb
・ソ#!/usr/bin/ruby -Ku ← typeが妙なものを出すのはどうかとは思うが、それはCPが違うので良いとして
puts('hello')
C:\Users\arton\tmp>ruby -v u8.rb
ruby 1.8.7 (2008-08-11 patchlevel 72) [i386-mswin32] ← なすすべがない
u8.rb:1: Invalid char `\357' in expression
u8.rb:1: Invalid char `\273' in expression
u8.rb:1: Invalid char `\277' in expression
C:\Users\arton\tmp>ruby -vKu u8.rb
ruby 1.8.7 (2008-08-11 patchlevel 72) [i386-mswin32] ← 打つ手もない
u8.rb:1: undefined local variable or method `・ソ' for main:Object (NameError)
C:\Users\arton\tmp>set PATH=c:\home\ruby-1.9\usr\bin;%PATH%
C:\Users\arton\tmp>ruby -v u8.rb
ruby 1.9.0 (2008-08-26 revision 18849) [i386-mswin32] ← やっほー
hello
というわけで、1.9を使おう! という結論。
多分、PATHの設定の戻し忘れか何かで1.9をいじっているときに1.8を動かして、BOM付きutf-8のスクリプトを処理できないと勘違いしたのだと思う。で、そう思ったまま32982を読んだので、BOM付きスクリプトの扱いもユーザー側に投げられたのかとさらに勘違いをしていた、ということでした。
_ なんか変だな
typeが相変わらず先頭に妙なものを出すのはともかく、
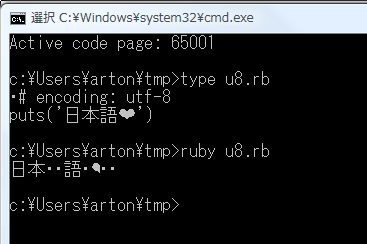
なぜ、putsの結果に余分なものが入るんだ?(むしろcmd.exeかコンソールのウィンドウシステムを疑っている。というのは、typeの結果も選択-反転を一度しないと正しく表示されないから)
_ MI
同じく木村さんのところのリスト。
SQLの書式設定ではMIを使うから、まったく違和感はないけど、そんなに変なものなのかな?
例)select to_timestamp('11:23:58', 'HH:MI:SS');
DB2とかだと違うのかも。
(単に異文化への無知から指摘しているのでなければ良いが、SQLを組み立てるための文字列ならむしろわかりやすい名前でしょう)
ジェズイットを見習え |
OracleもMIですね。→select to_char(sysdate, 'HH:MI:SS') from dual;
dualが肝ですねぇ。>Oracle
win32-unicode-testブランチもご覧頂けるとおもしろいかと思います。コンソールのCodePageを無視してUnicodeで表示、とか。(いや、現状それくらいしかありませんが)
それって、こないだruby-devに出されていた雪ダルマのやつですか? 確かにあれが標準になるとCMDクラッジ(無理矢理日本文字付きTTフォントの設定)しなくて済むのでうれしいかも。