日々の破片
| 著作一覧 |
2011-02-05
_ OSXのファイル名について教えてもらったこと
昨日の東京Ruby会議で、かわばたさんからNFCとかNFDとかについて教えてもらった。
Unicodeでは、文字の合成がサポートされている。たとえば「か」と濁点「゛」は合成することもできるし、「が」という1つの文字で登録もされている。しかし「あ」と濁点を組み合わせた1つの文字は登録されていない。でも「あ」と「゛」を組み合わせた「あ゛」も作れる。作った場合にどう表現するかはフォント(描画エンジンかも知れないな)に依存する(日本語よりも、おそらくウムラウトとかを使う欧州言語のほうで意味を持つ仕様だと思う)。
ということは、「が」という文字が実際には登録されている「が」という1つの文字なのか、それとも「か」+「゛」なのかは、特に文字列の比較をする場合には問題となりうる。人間としては等価として扱いたいが、コンピュータとしてはかたや1文字、かたや2文字だからだ。
そこで、アップルは考えた。そういうものはすべて分解して覚えておけばOK。というわけで、とかわばたさんの話は続く。lsすると「が」というファイルは2つに分けて表示される。(一方、マイクロソフトは何も考えていないらしい)
というわけで、合成文字をすべて分解する正規化をNFD、統合する正規化をNFCと呼ぶ(さらにNFKDとNFKCというのもあるそうだ)。
でも、今、10.6のUTF-8ターミナルで試したらちゃんと1文字として表示されている。ということはアップルは修正したようだ。
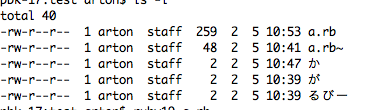 「るびー」の「び」と「−」の間は詰まっているように見える。
「るびー」の「び」と「−」の間は詰まっているように見える。
表示はともかくNFDされているかどうかを調べてみる。
次のスクリプトを実行する。
# coding: utf-8
Dir.entries('.').each do |d|
next if d =~ /^\.|rb~?$/ # このスクリプトやディレクトリは飛ばす。
printf("name='%s', size=%d, encoding=%s\n", d, d.size, d.encoding)
end
出力結果は以下となった。
pbk-17:test arton$ ruby19 a.rb name='か', size=1, encoding=UTF-8 name='が', size=2, encoding=UTF-8 name='るびー', size=4, encoding=UTF-8
sizeを見ると、「が」が2、「るびー」が4となっている。ということはかわばたさんが言った通り、分解されているということのようだ。
実はRubyはこのようなUnicode間の変換をサポートしている。
以下のようにencodeをかけるように修正する。
# coding: utf-8
Dir.entries('.').each do |d|
next if d =~ /^\.|rb~?$/
printf("name='%s', size=%d, encoding=%s\n", d, d.size, d.encoding)
d = d.encode('utf-8', Encoding::UTF8_MAC)
printf("name='%s', size=%d, encoding=%s\n", d, d.size, d.encoding)
end
上でおれはd = d.encode...とか書いているが、ここで情け容赦なくencode!と「Shift-1」を入力する心持ちを「破壊神への精神的脱皮」とか「破壊メソッド呼び出しの悦楽」と呼ぶというのもテーマにあったのを思い出した。おれはストイックだからどうにも悦楽を得られないらしい。しかしその一方で破壊的メソッドを呼び出す精神構造を「リソース貧困なる精神」、非破壊メソッドを呼び出す精神構造を大富豪と、ストイックという点では正反対に見なすことも可能なのだった。)
実行してみる。
pbk-17:test arton$ ruby19 a.rb name='か', size=1, encoding=UTF-8 name='か', size=1, encoding=UTF-8 name='が', size=2, encoding=UTF-8 name='が', size=1, encoding=UTF-8 name='るびー', size=4, encoding=UTF-8 name='るびー', size=3, encoding=UTF-8
encode後、「が」は1、「るびー」は3となった。
成瀬さんGJ!ということらしい。
(外部エンコーディングをUTF-8-MACとすれば最初から合成されるのかな? と試してみるかも)
追記:より深く知りたい人はあまのさんのページを参照すると良いと思います。
_ OSXでのファイル名比較
というわけで、ファイル名をスクリプトで比較する場合、何も考えないとうまくいかないことがある。
普通にエディターでutf-8でスクリプトを書くとそれはutf-8になるし、少なくとも
ruby 1.9.2p0 (2010-08-18 revision 29036) [x86_64-darwin10.4.0]
では、OSXのファイル名を勝手に合成のほうの正規化はしてくれない。
次のようにスクリプトを書いたら期待通りに動作(つまり、特定のファイル名を検出)した。
# coding: utf-8
Encoding.default_external = Encoding::UTF8_MAC
Encoding.default_internal = Encoding::UTF_8
RUBY = 'るびー'
printf("str='%s', size=%d, encoding=%s¥n", RUBY, RUBY.size, RUBY.encoding)
Dir.entries('.').each do |d|
next if d =‾ /^¥.|rb‾?$/
printf("name='%s', size=%d, encoding=%s¥n", d, d.size, d.encoding)
puts 'find!' if RUBY == d
end
実行結果を以下に示す。
pbk-17:test arton$ ruby19 a.rb str='るびー', size=3, encoding=UTF-8 name='か', size=1, encoding=UTF-8 name='が', size=1, encoding=UTF-8 name='るびー', size=3, encoding=UTF-8 find!
Dirクラスが読み込んで文字列を返した時点で、default_externalからdefault_internalに変換され、それがスクリプトのエンコーディング(マジックコメントで指定)で指定したものと一致している。
ではスクリプトをSJISにしたらどうなるんだろう?
と、試したら、スクリプトはSJIS、default_internalはutf-8なのでRUBYという文字列はshift_jisのままなので見つからない状態となった。ということは自動的にやらせるには、default_internalをスクリプトのエンコーディングに合わせてやる必要があるのかな。でも、そうするとスクリプトがライブラリで他の未知のスクリプトから呼ばれるとすると、メソッドに入った時点でdefault_internalを保存、設定、出る時点で復元してやらないとおかしくなるはずだ、というかおかしくなるだろう(呼び出し側に依存するけれど)。
と考えるとクロスプラットフォームで(externalが実行環境によって変わる)かつ、クロスエンコーディング(という言葉があるか知らないけれど、複数のエンコーディングによるスクリプトファイルで構成されたプログラム)は、すんなりとは書けないな。
ジェズイットを見習え |